DifyでRAG(Text Embedding + Rerank)をセルフホスティングしたい!(1) - モデルプロバイダーの準備
February 05, 2025
日本語を前提としたチャットボットを作ろうと、DifyでRAGする際の情報をググっていると、どこかしらのサービスのAPIを叩いて実現しているものばかり出てきてしまう。 そのため、全部オンプレのセルフホスティングでやろうとするとどうしていいやらまるでわからんとなりがちである。 そこで今回は、DifyでのRAG(Text Generation + Embedding + Rerank)を、全てオンプレで実現するための手順を取りまとめる。
Retrieval-Augmented Generation(RAG)ってなに?
RAGは、テキスト生成の際に何らかの情報を組み合わせて、生成の精度を向上させる手法である。 モデル自体に変更を加える手法と比較すると、低コストで新しい情報に適応できるというメリットがある。 RAG用のナレッジを得る方法として、一般的なデータベースや検索エンジンに加え、テキストをベクトル化したものを記録し、 それを元に検索するベクトルデータベースが用いられることが多い。
ベクトルデータベースを用いたRAGには、「推論モデル」、「Embeddingモデル」、「Relankモデル」の3つのモデルと、 任意のベクトルデータベースが必要となる。
- 推論モデル: 毎度おなじみテキスト生成に用いられるモデル
- Embeddingモデル(埋め込みモデル): テキストをベクトルの形に変換するためのモデル
- Rerankモデル: RAGの検索結果を評価し、よりよいと思われるものを優先するためのモデル
例えば、山形県に関するWikipediaの記事をデータベース化し、そこから検索する際は、次の図のような手順でおこなう。
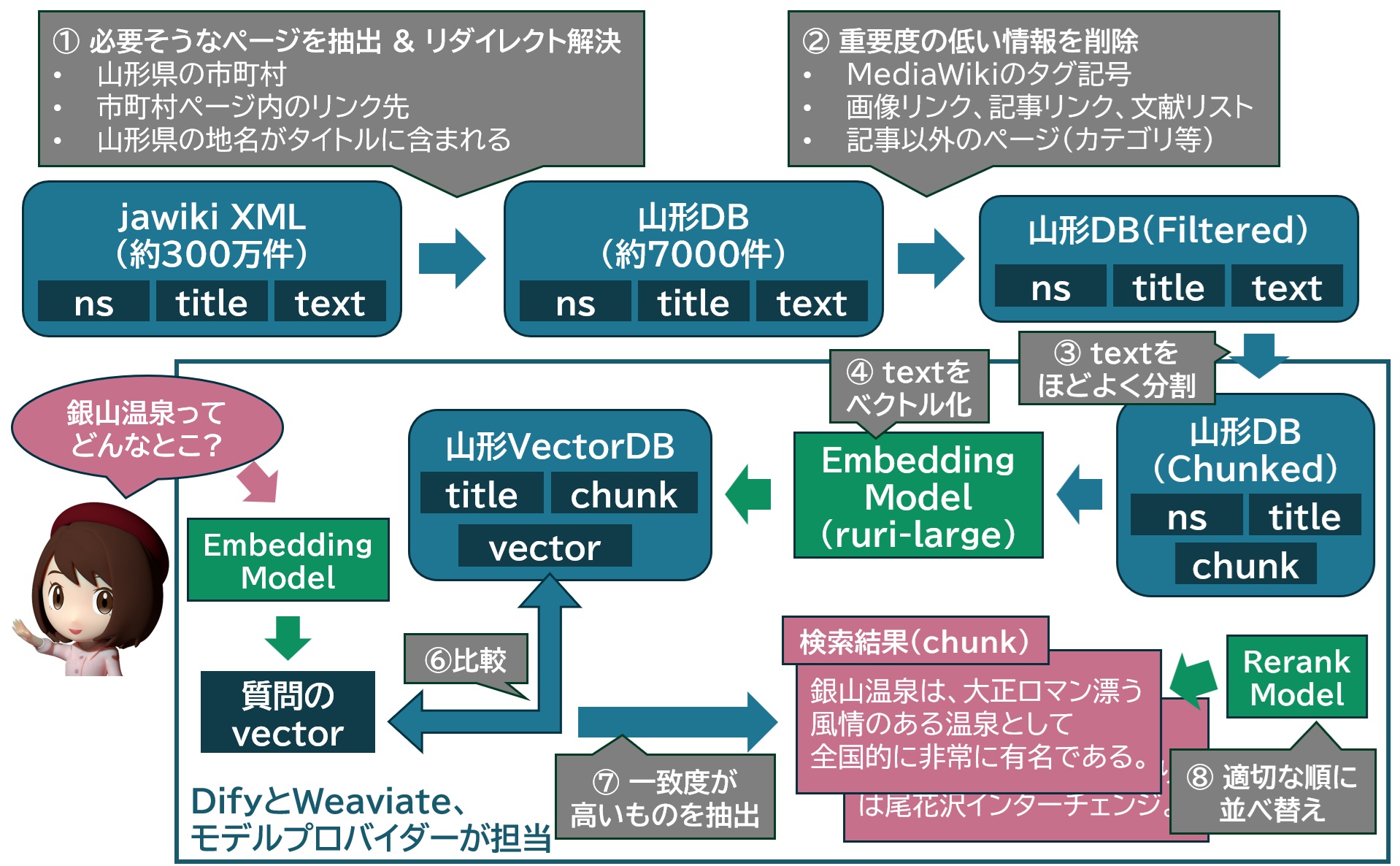
こうすることで、大元の推論モデルの学習時にはなかった情報や、学習から漏れ落ちた情報などを補足した上で生成がおこなえるようになる。
ベクトルデータベースについては、Difyはさまざまな実装をサポートしているが、 デフォルトではWeaviateが用いられるようである。 Dify経由で扱う際はデータベースの差異はほぼ意識せずに利用できるため、今回はそのままWeaviateを用いる。
Difyの用意
Difyのインストールは、公式githubの通り、Docker Composeを用いるのが手っ取り早い。
まずはソースコード一式を入手し、deploy用のブランチをてきとうに切っておく。
$ git clone https://github.com/langgenius/dify.git
$ cd dify
$ git switch -c deploy 0.15.2
次にdockerディレクトリに移動し、.env.exampleを元に.envファイルを作成する。
デフォルトのままだと各種パスワードがdifyai123456で決め打ちされているので、注意が必要である。
(もしここで詰まるようであれば、おとなしくてきとうなSaaSにお金を払って契約したほうがよい可能性が高い。)
$ cd docker
$ cp .env.example .env
# ここで.envをてきとうに編集
.envが記述できたら、docker compose upする。
$ docker compose up -d
デプロイが完了し、最初の管理者アカウントの設定が完了すると、次のようなトップページが表示される。
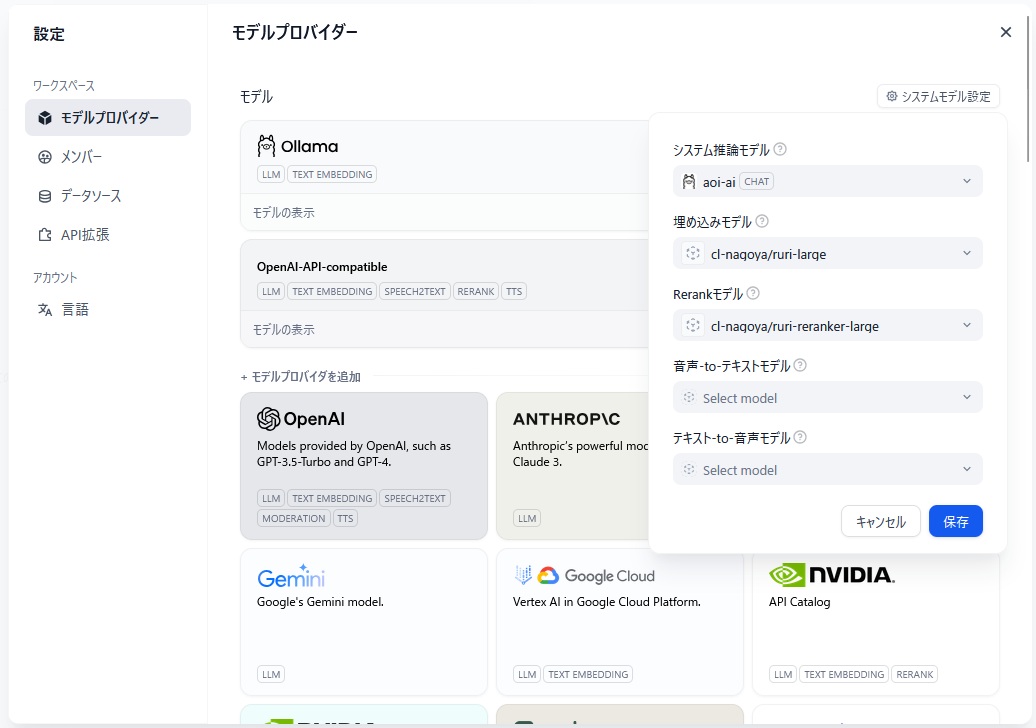
最初に設定が必要となるのは、「モデルプロバイダー」である。これは、右上のボタンのメニューから設定できる。 今回なんとかしたいのは、「モデルプロバイダー」の 「システム推論モデル」 、 「埋め込みモデル」 、 「Rerankモデル」 の3つである。
モデルとモデルプロバイダーの用意
推論・Text Embedding・Rerankのモデルプロバイダーを用意する。 今回は、次の3つのモデルを利用できるようにする。
- 推論: https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF
- Text Embedding: https://huggingface.co/cl-nagoya/ruri-large
- Rerank: https://huggingface.co/cl-nagoya/ruri-reranker-large
長くなるので、それぞれ別ページにまとめた。
おや? VRAMの ようすが…?
すべてのモデルをVRAM上にロードすると、8GBでは全然足りない模様。みんな大好きRTX 3060(12GB)が最低ラインとなりそう。
% nvidia-smi
Tue Feb 18 08:34:31 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 565.57.01 Driver Version: 565.57.01 CUDA Version: 12.7 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 Ti On | 00000000:01:00.0 Off | N/A |
| 0% 39C P8 9W / 165W | 9244MiB / 16380MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 250919 C ...rs/cuda_v12_avx/ollama_llama_server 5844MiB |
| 0 N/A N/A 1144702 C ...ake-openai-server/.venv/bin/python3 1498MiB |
| 0 N/A N/A 1239936 C ...ake-openai-server/.venv/bin/python3 1882MiB |
+-----------------------------------------------------------------------------------------+